Quickstart
This section provides basics steps to take before running PFD-kit
Easy Install
PFD-kit can be built and installed form the source with pip:
pip install git+https://github.com/ruoyuwang1995nya/pfd-kit.git
Job submission
PFD-kit comes with a simple CLI interface. For instance, a finetune workflow can be submitted using following command:
pfd submit finetune.json -t finetune
The finetune.json specifies imput parameters of the finetune task, whose details can be found in the examples directory.
It should be noted that PFD-kit is built upon the dflow package and utilized OPs from the DPGEN2 project, thus it is best to experience PFD-kit on the cloud-based Bohrium platform, though local deployment is also possible.
Tutorial: c-Si
This tutorial demmonstrates the general workflow of PFD-kit with a simple example of crystal Si in diamond structure. The relevant input files can be found at /examples/silicon. In this example, we need a efficient deep potential model of Si crytal with high accuracy for large scale atomic simulation, which can be easily generated from pretrained atomic through fine-tuning and distillation using PFD-kit.
Note: this tutorial may require Bohrium account.
Fine-tuning
We start from the latest DPA-2 pretrained model (DPA-2.3.0-v3.0.0b4), which is a highly transferable large atomic model with multiple prediction heads. One of the prediction heads is the Domains_SemiCond, it is trained with DFT calculations generated by the ABACUS software and includes major types of semiconductor material such as Si. Hence, we may fine-tuning our VASP Si model from the Domains_SemiCond head. In fine-tuning step, you need to prepare the model file of DPA-2 pretrained model and its associated training script, which can be downloaded from AIS square. You also need to prepare the pseudopotential file for Si. The directory tree of fine-tune step is as follows:
examples/
├── c_Si/
│ ├── finetune
│ | ├── DPA-2.3.0-v3.0.0b4.pt
│ │ ├── si_ft.json
│ │ ├── input_torch_medium.json
│ │ ├── INCAR.fp
│ │ ├── POSCAR
│ │ └── POTCAR
Note: the DPA-2 pretrained model can be downloaded from AIS square
The test dataset is extracted from DeePMD trajectories of crystal Si at 500 K and at pressures from 1 Bar up to 10000 Bar and is labeled using VASP with PBE pesudopotential. We first check the accuracy of the pretrained model on the test set. After extracting energy bias caused by different DFT setting (pseudopotential selection, etc.), the prediction error of the Domains_SemiCond head is actually not bad, as shown in Figure 1.
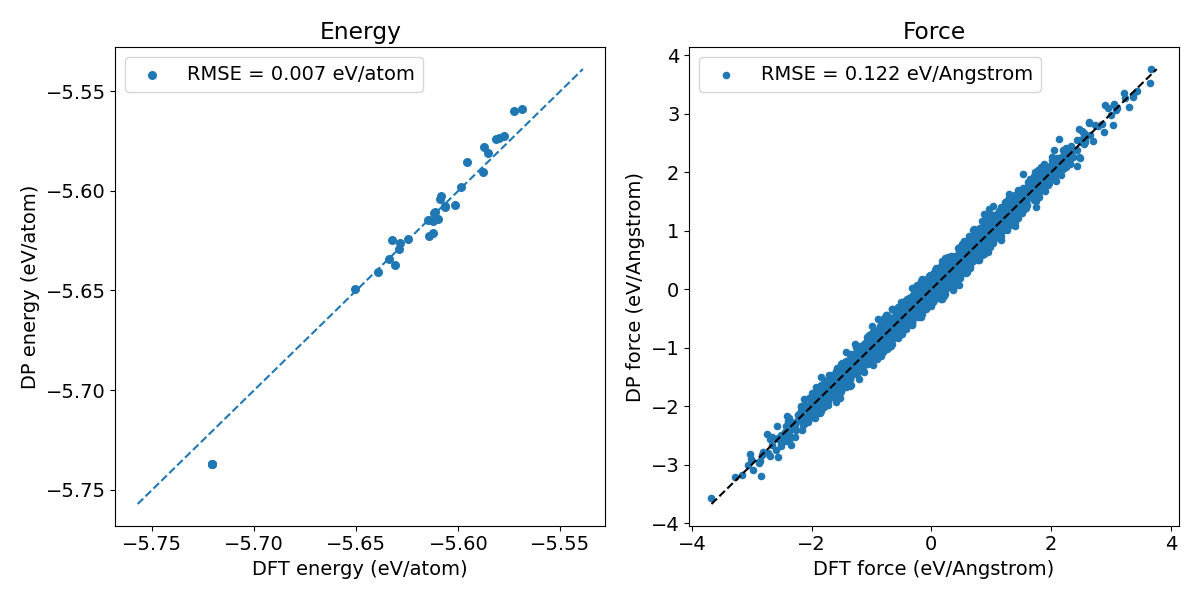
Figure 1. Prediction error of pretrained DPA-2 models on crystal Si.
However, the accuracy, escpecially that of force predition, may not be optimal, and the pretrained model, with its huge, complex descriptor, is inefficient for atomic simulation in terms of both computation and memory consumption. Hence, we first use PFD-kit to fine-tune a more accurate Si model, generate a much faster, but almost as accurate, “standard” deep potential model for Si crystal through model distillation.
Preparing input script
Then we needs to prepare the input script file si_ft.json. The input script is a JSON file which contains multiple entries defining various aspects of the PFD workflow. In this tutorial, you should modify the bohrium_config section of the script, so that the PFD-kit workflow can access the cloud-based server.
"bohrium_config": {
"username": "urname",
"password": "123456",
"project_id": 123456,
"_comment": "all"
},
Note: The remaining part of this section can be skipped if you want to run the job first.
Then, you need to set up the computation nodes to specify the images and machine types for various computation tasks. Images contain the software installation and neccesary dependencies, and upon execution a container (i.e.,a computation node) would be generated from an image and run by physical machine of selected type. There is a default step setting in the default_step_config, which applies to all computation nodes unless otherwise specified.
"default_step_config": {
"template_config": {
"image": "registry.dp.tech/dptech/ubuntu:22.04-py3.10"
},
"executor": {
"type": "dispatcher",
"image_pull_policy": "IfNotPresent",
"machine_dict": {
"batch_type": "Bohrium",
"context_type": "Bohrium",
"remote_profile": {
"input_data": {
"job_type": "container",
"platform": "ali",
"scass_type": "c2_m4_cpu"}
}
}
}
},
Here, a lightweigh Ubuntu image and a cheap machine (”c2_m4_cpu”) is selected. You can check the availiable image and machine type in the Bohrium pages. In fine-tuning, data exploration, data labeling and model training requires extensive computation resources, thus these nodes should be assigned to much more powerful physical machines. We can specify the settings for these key nodes in the step_configs.
"step_configs": {
"run_fp_config": {
"template_config": {
"image": "_vasp_image"
},
"continue_on_failed":true,
"continue_on_success_ratio": 0.9,
"executor": {
...
}
},
"run_explore_config": {
"template_config": {
"image": "registry.dp.tech/dptech/deepmd-kit:3.0.0b4-cuda12.1"
},
"continue_on_success_ratio": 0.8,
"executor": {
...
}
},
"run_train_config": {
"template_config": {
"image": "registry.dp.tech/dptech/deepmd-kit:3.0.0b4-cuda12.1"
},
"executor": {
...
}
}
},
Note: to use the VASP image on Bohrium , you may need an authorized license. Otherwise you can build your own image.
Note: images with correct version number must be selected! Since we use the
DPA-2.3.0-v3.0.0b4model, thus theregistry.dp.tech/dptech/deepmd-kit:3.0.0b4-cuda12.1image with corresponding DeePMD-kit version is chosen for model training and MD exploration.
Then the parameters defining workflow tasks in the example si_ft.json file. Firstly, the task type (in this case “finetune”) must be specified. Here we skip the initial data generation and training as the Domains_SemiCond branch already contains quite a lot information of crystal Si, and instead directly explore new Si configurations with the pretrained model.
"task":{
"type":"finetune",
"init_training": false,
"skip_aimd": true
}
The inputs section includes essential input parameters and model files. type_map maps the type embedding of pretrained model to corresponding element name. The pretrained model path also needs to be specified.
"inputs":{
"type_map":["Li","..."],
"base_model_path": "DPA2_medium_28_10M_beta4.pt"
}
The conf_generation section defines how perturbed structures are generated from initial structure files. Here the 5 randomly perturbed structures of a 2x2x1 Si supercell (”POSCAR”). In this case, atoms within the perturbed structure would be displaced by a maximum of 0.05 Angstrom, and the lattice constant would experience a 3 % contraction or extension.
"conf_generation": {
"init_configurations":
{
"fmt": "vasp/poscar",
"files": [
"POSCAR"
]},
"pert_generation":[
{
"conf_idx": "default",
"atom_pert_distance":0.05,
"cell_pert_fraction":0.03,
"pert_num": 5
}
]},
The exploration section defines the data exploration, it explores new Si configurations with molecular dynamics (MD) simulations using LAMMPS and add them into the training set for the next iteration. Here the exploration step only has one “stage”, which generate new frame by running NPT simulation at 1000 K and at various perssure starting from one of the 5 perturbed Si structure. Each LAMMPS trajectory runs for 1000 steps, and a frame is extracted for subsequent labeling (i.e., DFT calculation). The exploration stage would run iteratively until convergence. The exploration converges when the root mean squre error (RMSE) of atomic force prediction falls below 0.06 eV/Angstrom.
"exploration": {
"type": "lmp",
"max_iter":2,
"convergence":{
"type":"force_rmse",
"RMSE":0.06,
"conf_filter":[
{"type":"force_delta",
"thr_l": 0.05,
"thr_h": 0.2
}
]
},
"filter":[{
"type":"distance"
}],
"config": {
"command": "lmp -var restart 0",
"head":"Domains_SemiCond",
"model_frozen_head": "Domains_SemiCond"
},
"stages":[[
{ "_comment": "group 1 stage 1 of finetune-exploration",
"conf_idx": [0],
"n_sample":1,
"type": "lmp-md",
"ensemble": "npt",
"dt":0.002,
"nsteps": 1000,
"temps": [1000],
"press":[1,1000, 10000],
"trj_freq": 100
}]]},
Note: when fine-tuning from a specific branch of deep potential model,
headandmodel_frozen_headmust be specified in theexploration/config.
The fp section defines DFT calculation settings. The path to the VASP input file as well as the pseudopotential file for each element are specified. The VASP command at fp/run_config/command should be configured according to the machine type for optimal performance.
"fp": {
"type": "vasp",
"task_max": 50,
"run_config": {
"command": "source /opt/intel/oneapi/setvars.sh && mpirun -n 32 vasp_std"
},
"inputs_config": {
"incar": "INCAR.fp",
"pp_files": {
"Si": "POTCAR"
},
"kspacing":0.2
}
},
The train section defines the type of pretrained model and the specific training configuration. The detailed training script can be provided either as a dict or in an additional script (as shown below). It is crucial to provide the path to the pretrained model in the init_models_paths entry.
"train": {
"type": "dp",
"config": {
"impl": "pytorch",
"head":"Domains_SemiCond",
},
"template_script": "train.json",
}
Submit job
After modifying the input script, you can submit the fine-tune job using CLI:
pfd submit si_ft.json
With a successful submission, a workflow ID and a link to the Argo server would be printed out to the console. You can check the link to monitor the workflow progression. Additionally, you can also check the completed exploration cycles with the status command:
$ pfd status si_ft.json WORKFLOW_ID
+-------------+------------+------------+--------------+---------------+---------+---------------------+------------------+-------------+
| iteration | type | criteria | force_rmse | energy_rmse | frame | unconverged_frame | selected_frame | converged |
+=============+============+============+==============+===============+=========+=====================+==================+=============+
| 000 | Force_RMSE | 0.06 | 0.102363 | 101.472 | 33 | | 30 | False |
+-------------+------------+------------+--------------+---------------+---------+---------------------+------------------+-------------+
| 001 | Force_RMSE | 0.06 | 0.0375587 | 0.00145353 | 33 | | 4 | True |
+-------------+------------+------------+--------------+---------------+---------+---------------------+------------------+-------------+
The two iterations of exploration are executed before convergence. In the first iteration (000), 33 frames are selected for DFT calculation and 30 of them are added to the training set for fine-tuning. In the next iteration (111), another 33 frames are labeled, but the fine-tuned model from the last iteration already achieves sufficient accuracy. Hence, the training step at iteration 001 is skipped and the whole exploration ends. The final model can be downloaded to ~/si_ft_res/model/task.0000/model.ckpt.pt using download command:
pfd download si_ft.json WORKFLOW_ID -p si_ft_res
The fine-tuned model exhibits much better accuracy on the test set, with a high energy prediction error of 0.002 eV/atom and a force prediction error of 0.056 eV/Angstrom, respectively.
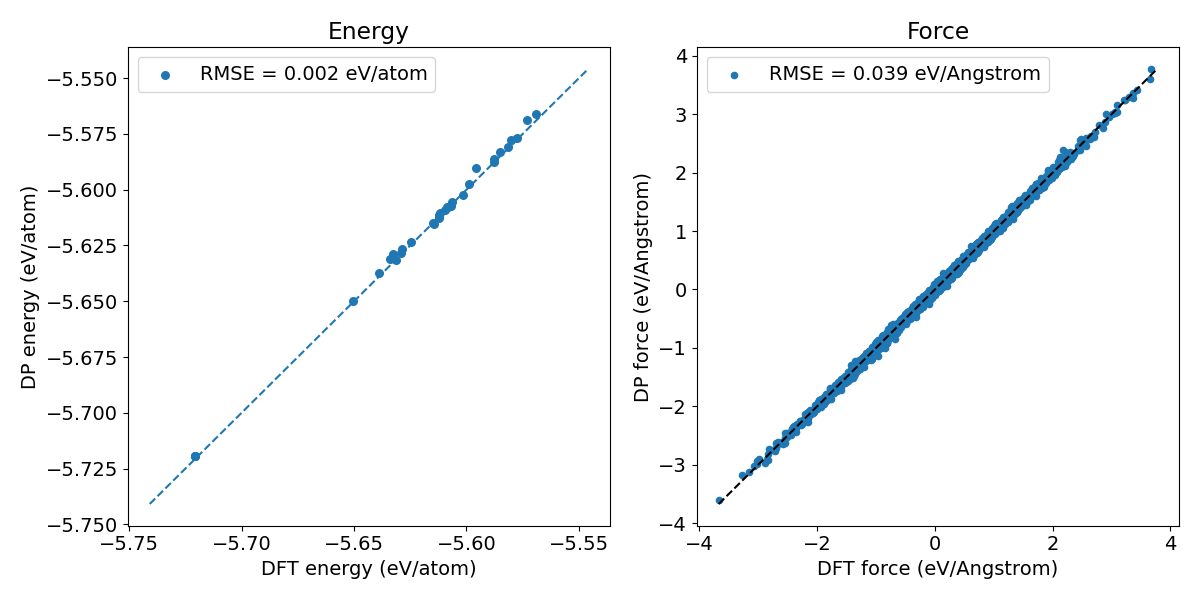
Figure 2. Prediction error of the fine-tuned Si model.
Distillation
As mentioned, the structure of the fine-tuned model is identical to that of the pretrained base model, therefore it is inefficient for large scale atomic simulaiton despite the high accuracy. Fortunately, the complexity of the fine-tuned model is largely redundant given the narrow chemical and configurational space associated with crystal Si. It is then possible to transfer the knowledge of the fine-tuned to a new, lightweight model through a process known as “knowledge distillation”. In model distillation, the fine-tuned model is analogous to an AIMD engine generating training data (but much more efficient!). These data generated by the fine-tuned model would then be used to train the end model for large scale atomic simulation.
The directory tree of the distillation step is as follows:
examples/
├── c_Si/
│ ├── distillation
│ | ├── model.ckpt.pt
│ │ ├── POSCAR
│ │ ├── si_dist.json
│ │ └── dist_train.json
Note: you should copy the fine-tuned model file here.
Preparing input script
The input script for model distillation is very similar to that of fine-tuning, but there are a few key differences. Obviously, the task type needs to be “dist”. You also needs to specify the path to teacher model file and its type (default as “dp”). The training script for the end model, “train.json”, would train a standard DeePMD model with the local se_atten_v2 descriptor with the local attention turned off.
"task":{"type":"dist"},
"inputs":{
"type_map":["..."],
"teacher_model_path":"model.ckpt.pt",
"teacher_model_style":"dp"
},
"conf_generation":{...},
"train":{
"type": "dp",
"config": {},
"template_script": "dist_train.json"
},
"exploration":{
...,
"test_set_config":{
"test_size":0.2
}
}
Submit job
Submit job with the same submit command
pfd submit si_dist.json
The exploration process should converge after one iteration, where 1500 frames are generated and labeled by the fine-tuned model, among which 1350 frames are utilized as training set and the remaining frames as test set.
+-------------+------------+------------+--------------+---------------+---------+---------------------+------------------+-------------+
| iteration | type | criteria | force_rmse | energy_rmse | frame | unconverged_frame | selected_frame | converged |
+=============+============+============+==============+===============+=========+=====================+==================+=============+
| 000 | Force_RMSE | 0.06 | 0.0462139 | 0.000844013 | 1 | | 1 | True |
+-------------+------------+------------+--------------+---------------+---------+---------------------+------------------+-------------+
Upon successful completion, the end model can be generated and downloaded. The end model exhibits better accuracy than the pretrained model.
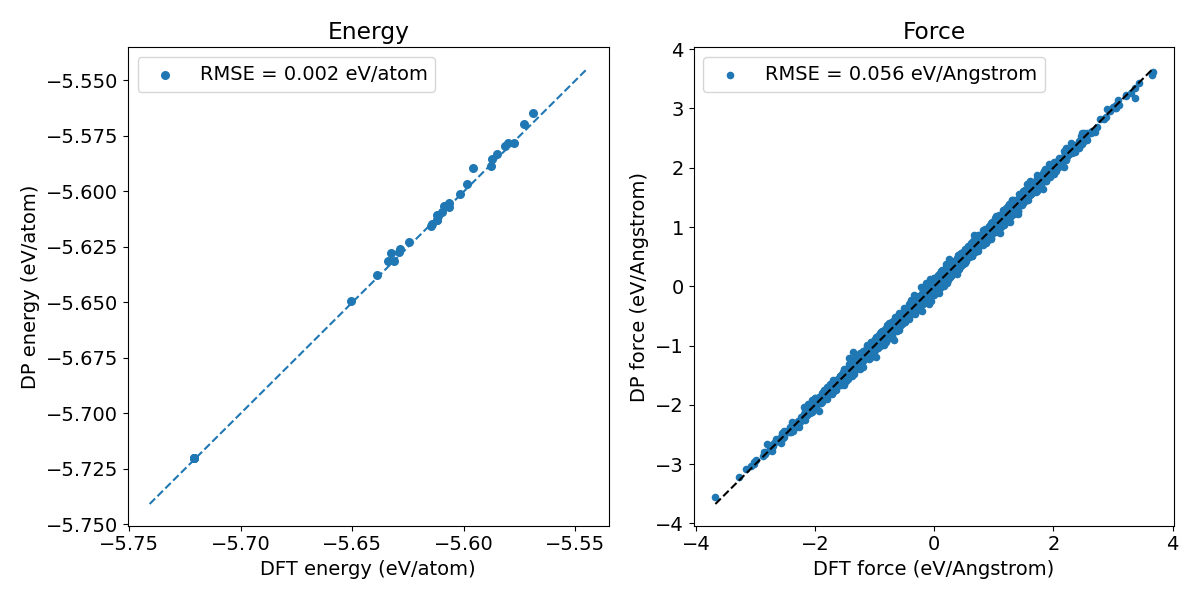
Figure 3. Prediction error of the Si model generated through knowledge distillation.
Note: the whole process would take about 3 hours to complete (1.5 hour each for fine-tuning and distillation)