Overview
PFD-kit automates the fine-tuning and distillation process of pre-trained atomic models, such as DPA-2. It enables practical atomistic simualtion with the highly transferable, but computationally expensive pre-trained models. PFD-kit is built upon the DPGEN2 workflow and supports the Deep Potential models. The best experience of PFD-kit is found on Bohrium platform.
Backgrounds
Machine learning force fields (e.g., Deep Potential) combine quantum mechanics principles with data-driven algorithms to achieve large-scale atomic simulations with first-principle accuracy. However, machine learning force fields often suffer from limited transferability, high costs in data generation, and extensive human inteference during training, which lead to significant resource expenses. These challenges make training machine learning force fields a difficult task for practical material systems. Figure 1 illustrates two typical material systems. The first is carbon materials. Training for bulk carbon with a small unit cell seems easy, but the carbon surface structures or the disordered phases require large supercells and extensive sampling within the huge configuration space, making training almost intractable. The second is high-entropy alloys. In these materials, spatial arrangements of atoms of different elements lead to varying interactions, and as the number of elements increases, the possible chemical space grow exponentially, making comprehensive sampling nearly impossible.

Figure 1. Typical material systems that pose significant challenges to force field training.
Large atom models (LAM, such as DPA-2) pre-trained on extensive datasets and embed transferable knowdge across vast chemical and configuration space, potentially address the above issues. Utilizing the transferable knowledge, fine-tuning of the pretrained LAM can yield high-accuracy among specific material domains with much smaller data sets, usually only one-tenth or even one-hundredth of the data required for training from scratch. The fine-tuned models can predict energy and atomic forces with DFT accuracy at much lower costs, replacing DFT for efficient data sampling and labeling. After extensive data sampling, knowledge distillation can create distilled models from the sampled data. The distilled model has fewer parameters, but still accurately predicts the specific domain of interst. Thus, it is suitable for large scale simulations of millions of atoms over a long periods of time (e.g., nanoseconds). Possible application include two-dimensional materials, metamaterials, semiconductor materials, energy materials, and alloys.
PFD-kit streamlines the above process, automatically generate from pre-trained model (P) an end model through fine-tuning (F) and distillation (D). PFD-kit reduces the time and computational costs of force fields generation by an order of magnitude compared to traditional from-scratch method, and requires with minimal human interference, thus significantly accelerates high-throughput computing and complex material simulations.
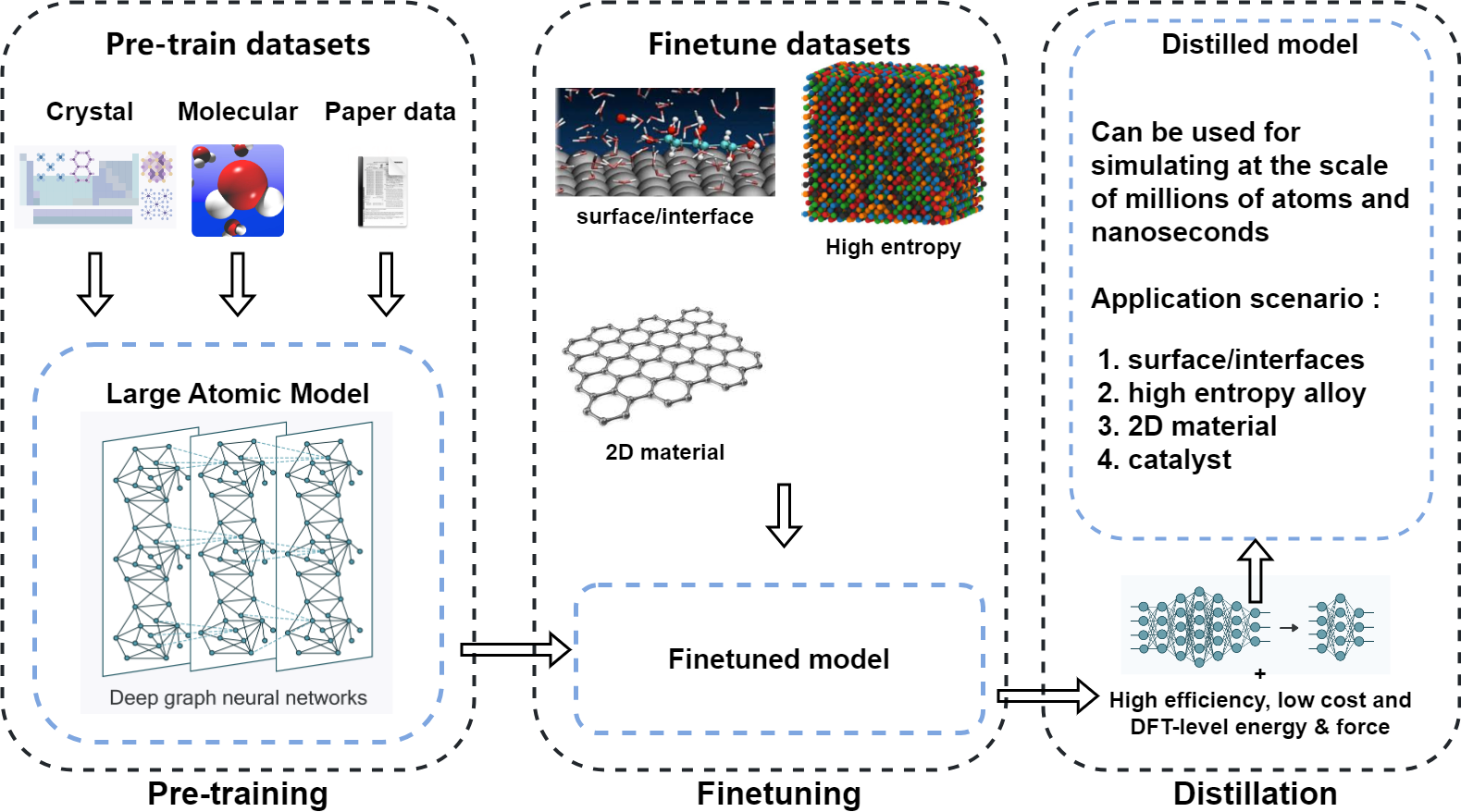
Figure 2. The general conception of PFD-kit workflow.
Workflows
Fine-tune
Fig.1 shows the schematic of fine-tuning workflow. Given the initial structures of fine-tuning systems, the workflow generates perturbed structures, and executes a series of short ab initio molecular dynamics (AIMD) simulation based upon randomly perturbed structures. The pre-trained model is firstly fine-tuned by the AIMD dataset, then MD simulation with the fine-tuned model searches new configurations, which are then labeled by first-principle calculation softwares. If the fine-tuned model cannot predict the labeled dataset with sufficient accuracy, the collected dataset would be added to the fine-tuning training set, and the train-search-label process would iterate until convergence.
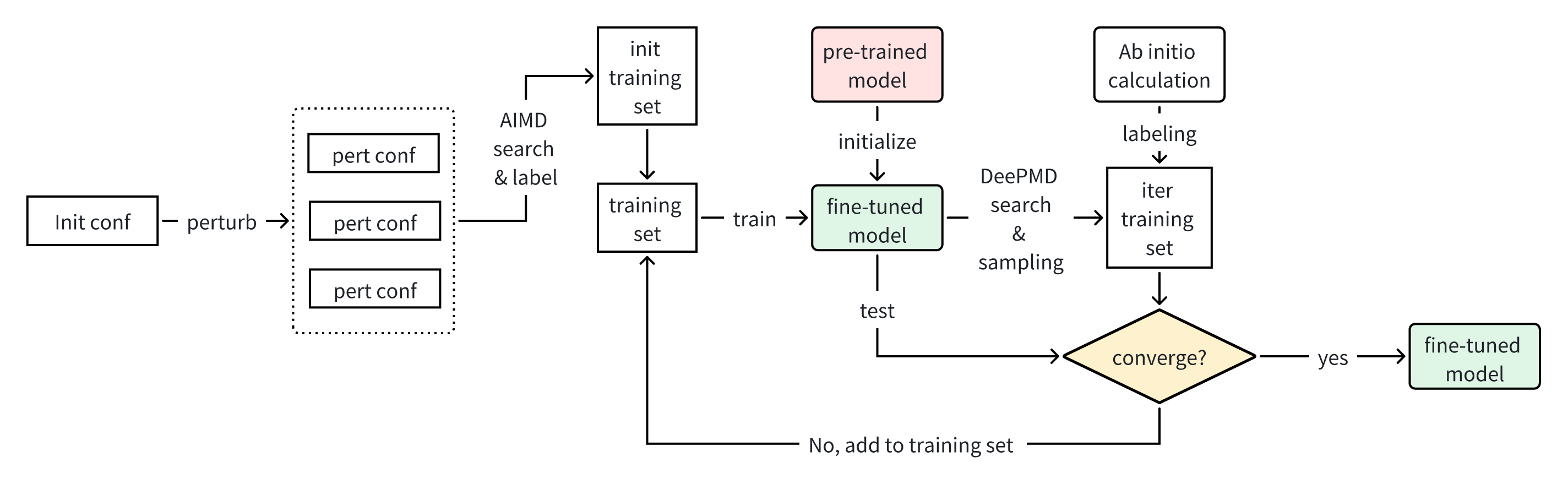
Figure 3. Schematics of fine-tune workflow.
Distillation
A lightweight model can be generated from a fine-tuned model through distillation, which enables much faster simulation. The distilled model can be generated with training data labeled by the fine-tuned model. Figure 2 shows the schematic of the distillation workflow.
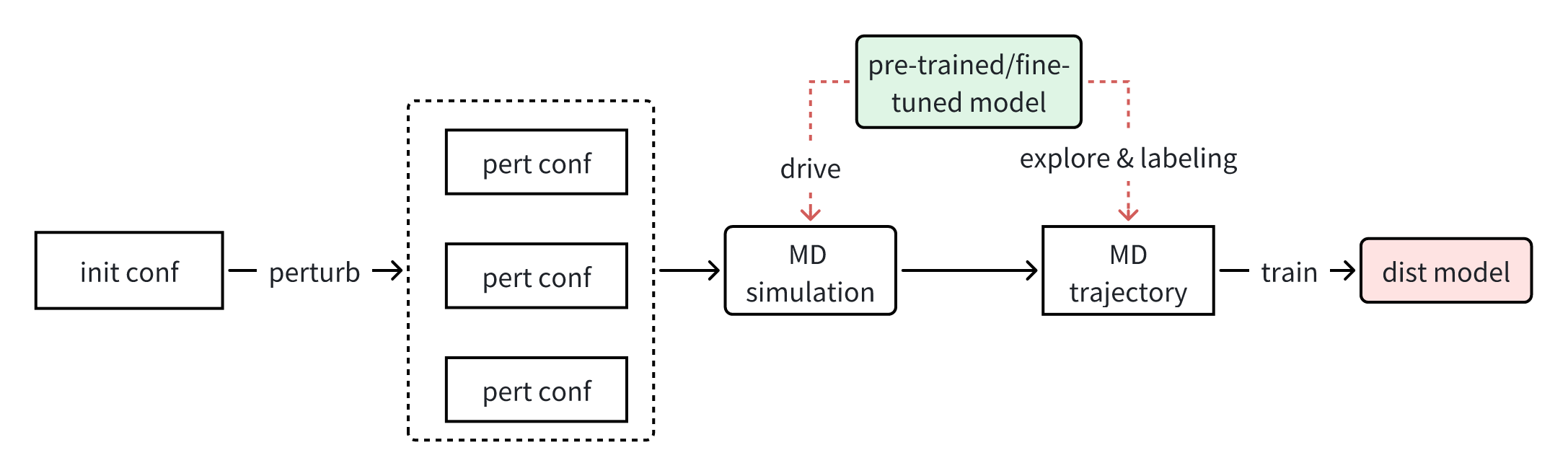
Figure 4. Schematics of distillation workflow.